The purpose of this article is to discuss and share some insight on real life issues caused by BGP 3rd party next hop.
What is Third Party Next Hop in BGP?
lets get definitions out of the way by saying Third Party Next Hop describes the unusual case where dynamically received eBGP routes happen to have a next hop address that differs from the neighbour your peering with and from whom you learnt the said routes. The normal behaviour in eBGP peering is that the next hop address is always updated with its own as opposed to the originator however there is an exception to this rule.
3rd party Next Hop happens when the routes are learnt from and passed onto neighbours on the same LAN segment and the next hop address isn’t updated so return traffic does end up asymmetrically routing between receivers and senders.
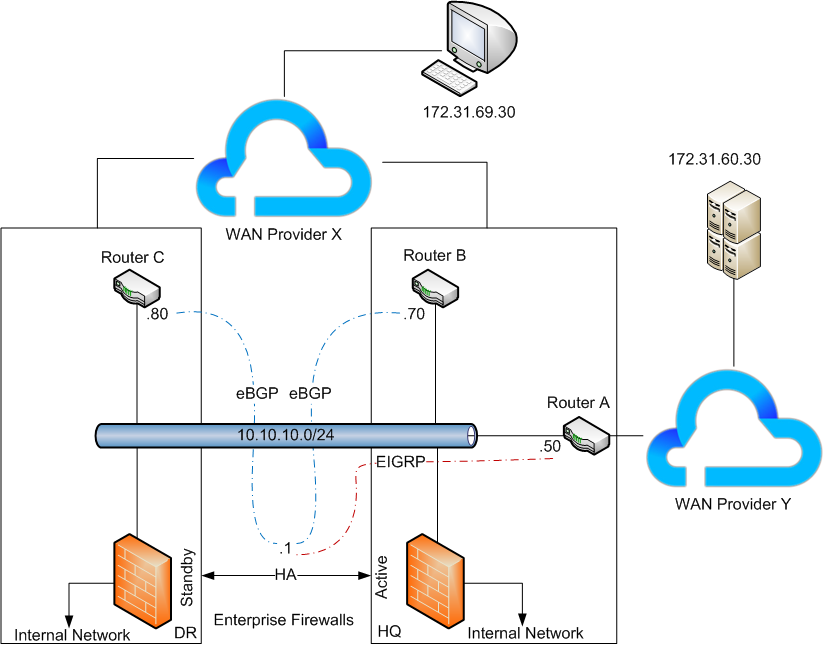
In the above example we have an active/standby firewalls who are responsible for redistributing EIGRP routes from WAN provider Y to BGP route to WAN provider X and vice versa.
As we have both the EIGRP adjacency as well as BGP peering having over the same LAN segment, the firewalls learn the Server subnet with a next hop address of 10.10..10.50 and instead of advertising this redistributed prefix onto 10.10.10.70 7 .80 with an updated next hop address of .1 (it’s self), routes are advertised with their next hop address of .50 completely unchanged.
This is effect leads to be asymmetric routing where the routing traffic from WAN provider X will bypass the firewalls and route directly to the WAN provider Y.
In a VPLS solutions where all sites communicate over a single LAN segment, you’d probably want the next hop address to the remain unchanged to avoid sub optimal routing and potential bottlenecks but at the same time, where you have statefull firewalls in the path or participating in routing, you must ensure traffic is symmetric in most cases. an Active-Active setup with session sync would work but s.
In our example, users couldn’t access the server, although ICMP appeared to work so I had to troubleshoot.
Finding the problem.
We all know ICMP doesn’t really prove connectivity so we performed a number of TCP test replicating the failure scenario. Then we began running packet capture to determine what why TCP was failing whilst ICMP was working.
Server Side Wireshark capture:
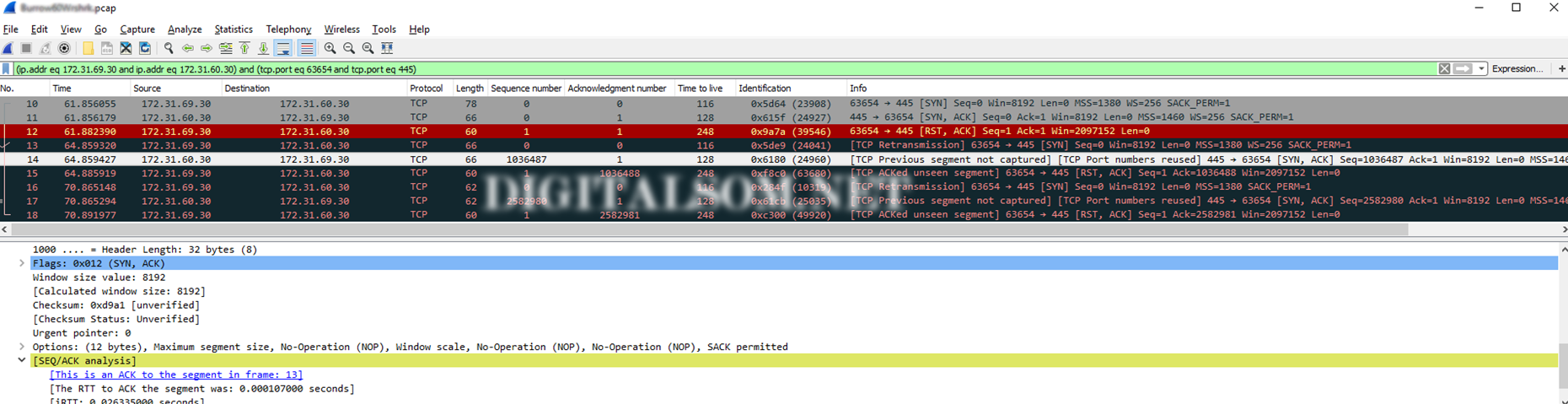 Note the sequence of events.
Note the sequence of events.
- Receives a SYN packet (seq 0, ack 0) from 69.30 with TTL 116(128-116= 12 hops away)
- Responds by sending a SYN,ACK packet to 69.30 with TTL 128(Locally originated)
- Receives a RST,ACK packet from 69.30 with TTL 248(255-248 = 7 hops away)
- Receives a retransmitted SYN packet (seq 0, ack 0) from 69.30 with TTL 116 – indicates remote server doesn’t receive
- Responds by sending a SYN,ACK packet to 69.30 with TTL 128(Locally originated)
- Received a RST,ACK packet from 69.30 with TTL 248(255-248 = 7 hops away which maybe the firewall, I need to check the traceroute to be sure)
Note so far:
- Remote Server (69.30) clearly uses a default TTL of 128 but a device with a default TTL of 255 is responding on its behalf with RST,ACK which is a combination of ACK the received packet as well as RST to close the TCP session. Typically seen as response from closed ports on devices who acknowledge getting your packet but at the same time want to let you know they’re not talk to you on that port.
The solution:
The solution is to modify the the next hop advertised by applying the next-hop-self command which will ensure returned advertising router is always used in the return path. This is a default behaviour in eBGP but if peering is configured between multiple peers across the same layer2 segment then originating nodes are imported as the next hop for each prefix.